


Veri Tabanındaki Değişiklikleri Anında Yakala: Debezium


İçindekiler
2. CDC Nedir?
3. Kafka Connect Nedir?
4. Debezium Nedir
5. Veri Aktarımında Alternatif Yaklaşımlar
5.1. Veri Tabanı Seviyesinde Aktarım
5.2. Dağıtık İşlem (Distributed Transaction) İle Aktarım
5.3. Kafka Connect ile Aktarım
6. Transaction Log Tailing Nedir?
7. Logical Replication Nedir?
8. Postgres Tablolarında Kopya Kimliği
8.1. Kopya Kimliği Konfigürasyonları
8.2. Ara Tablolarda Kopya Kimliği
9. Transaction Log Tailing Akış Şeması ve Yayınlama
10. Bağlayıcı Konfigürasyonları
10.1. Anlık Görüntü (İnitial Snapshot - snapshot.mode) Konfigürasyonu
10.2. Kalp Atışı (Heartbeat - heartbeat.interval.ms) Konfigürasyonu
10.2.1. WAL Dosyası Şişmesi Sorunu ve Heartbeat
10.2.2. WAL Dosyası Şişmesi Çözümü ve Heartbeat Action Query
11. Topic Konfigürasyonları
11.1. Log Compaction (Kayıt Sıkıştırma)
11.2. Tombstone Mesajlar
12. Debezium İçsel Topicleri
12.1. Konum (Offset) Topic
12.2. Config Topic
12.3. Durum (Status) Topic'i
13. Single Message Transform (Mesaj Dönüştürme)
13.1. Örnek kullanım: Route Transformasyonu
13.2. Sık Kullanılan Transformasyonlar
13.2.1. Cast (Tip Dönüştürme)
13.2.2. ExtractField (Alan Çıkarma)
13.2.3. Flatten (Yapıyı Düzleştirme)
14. Özel Transformasyonlar
15. Kafka'da Eş Güdümlülük (İdempotency)
15.1. İdempotent Tüketici Oluşturmak İçin Özel Transformasyon
16. Debezium İle Outbox Pattern Optimizasyonu
17. Debezium İle İlişkisel Verileri Aktarma
17.1. İlişkisel Veri Aktarımında Kullanılabilecek Yaklaşımlar
17.1.1. Veri Denormalizasyonu
17.1.2. KSQL
1. Giriş
Dağıtık mimarinin ve mikroservislerin yaygınlaşmasıyla olay tabanlı (event based) sistemlere olan ihtiyaç artmıştır. Hem veri tabanları arasında gerçek zamanlı veri aktarımı sağlamak hem de veri tabanı seviyesindeki değişiklikleri olay tabanlı olarak iş kurallarımızın akışına almak ihtiyacı doğmuştur. CDC (Change Data Capture - Veri Değişikliği Yakalama) araçları hem bu ihtiyaçlara cevap verirken hem de veri tabanı üzerine bindirilen yükü azaltarak mikroservis ekosistemine uyum sağlamaktadır. Bu araştırma serisinde CDC’nin temel prensiplerinden, bir CDC aracı olarak Debezium’dan ve arkasındaki teknolojiden bahsedilmiş, veritabanları arasında gerçek zamanlı veri senkronizasyonunun nasıl sağlanabileceği anlatılmış; Debezium’un CQRS (Command Query Responsibility Segregation - Komut Sorgu Ayrımı), Outbox Pattern (Giden Kutusu Deseni) gibi tasarım desenlerini gerçekleştirmede nasıl kullanılabileceği gösterilmiştir.
2. CDC nedir?
CDC bir veri tabanında gerçekleşen değişikliği (ekleme, güncelleme, silme vs.) yakalama olayıdır.
Değişikliği yakalama işlemi genellikle gerçek zamanlıdır ve yakalanan değişiklik; harici sistemlere aktarılır.
Yakalanan değişiklik 3. parti uygulamalara aktarılarak veri tabanı senkronizasyonu veya mesaj kuyruğu sistemlerine gönderilerek farklı amaçlar için kullanılabilir.
3. Kafka Connect nedir
Şekil 1: Kafka Connect mimarisi
Kafka Connect, connector(bağlayıcı) adı verilen bileşenleri kullanarak Apache Kafka ile harici sistemleri entegre eden bir araçtır. Birçok sistem için (JDBC, S3, Elasticsearch) kullanıma hazır bağlayıcılar sunmaktadır.
- Bir kaynak sistemden Kafka’ya veri yollayan bağlayıcılara Source Connector
- Kafka’dan bir hedef sisteme veri yollayan bağlayıcılara ise Sink Connector
adı verilmektedir.
4. Debezium Nedir
Debezium, Kafka Connect üzerine inşa edilmiş açık kaynak kodlu bir CDC platformudur. Yaygın olarak kullanılan veri tabanları için (MySql, PostgreSQL, MongoDB vb.) Kafka bağlayıcılarını gerekli tüm eklentileriyle birlikte kullanıma hazır şekilde içerisinde barındırır.
CDC araçlarının en yaygın kullanım alanlarından biri de veri tabanları arasındaki senkronizasyonu gerçek zamanlı olarak sağlamaktır.
5. Veri Aktarımında Alternatif Yaklaşımlar
5.1. Veri Tabanı Seviyesinde Aktarım
İki veri tabanı arasında veri aktarımı gerçekleştirmek için alternatif yollar da bulunmaktadır. Bunlardan bir tanesi; veri tabanı seviyesinde aktarım gerçekleştirmektir ki birçok veri tabanı bu özelliği desteklemektedir.
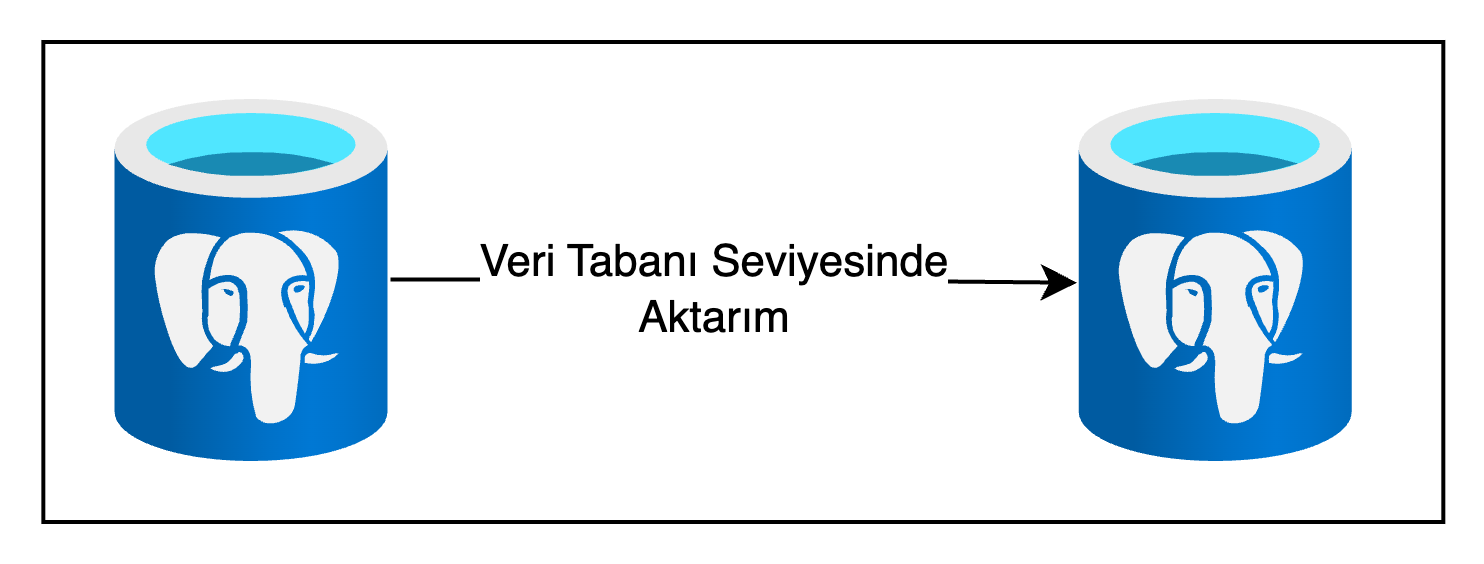
Şekil 2: Veritabanı seviyesinde aktarım
Postgres, Mysql gibi ilişkisel veri tabanları için mantıksal çoğaltma(logical replication), akış replikasyonu(streaming replication) gibi alternatifler, Cassandra gibi NoSQL veri tabanları için ise gömülü veri aktarımı mekanizmaları bulunmaktadır.
Ancak bu yaklaşım kaynak ve hedef veri tabanının aynı olmasını gerektirdiğinden son derece kısıtlayıcıdır ve her iki veri tabanının birbiriyle uyumlu bir versiyonda olmasını gerektirmektedir.
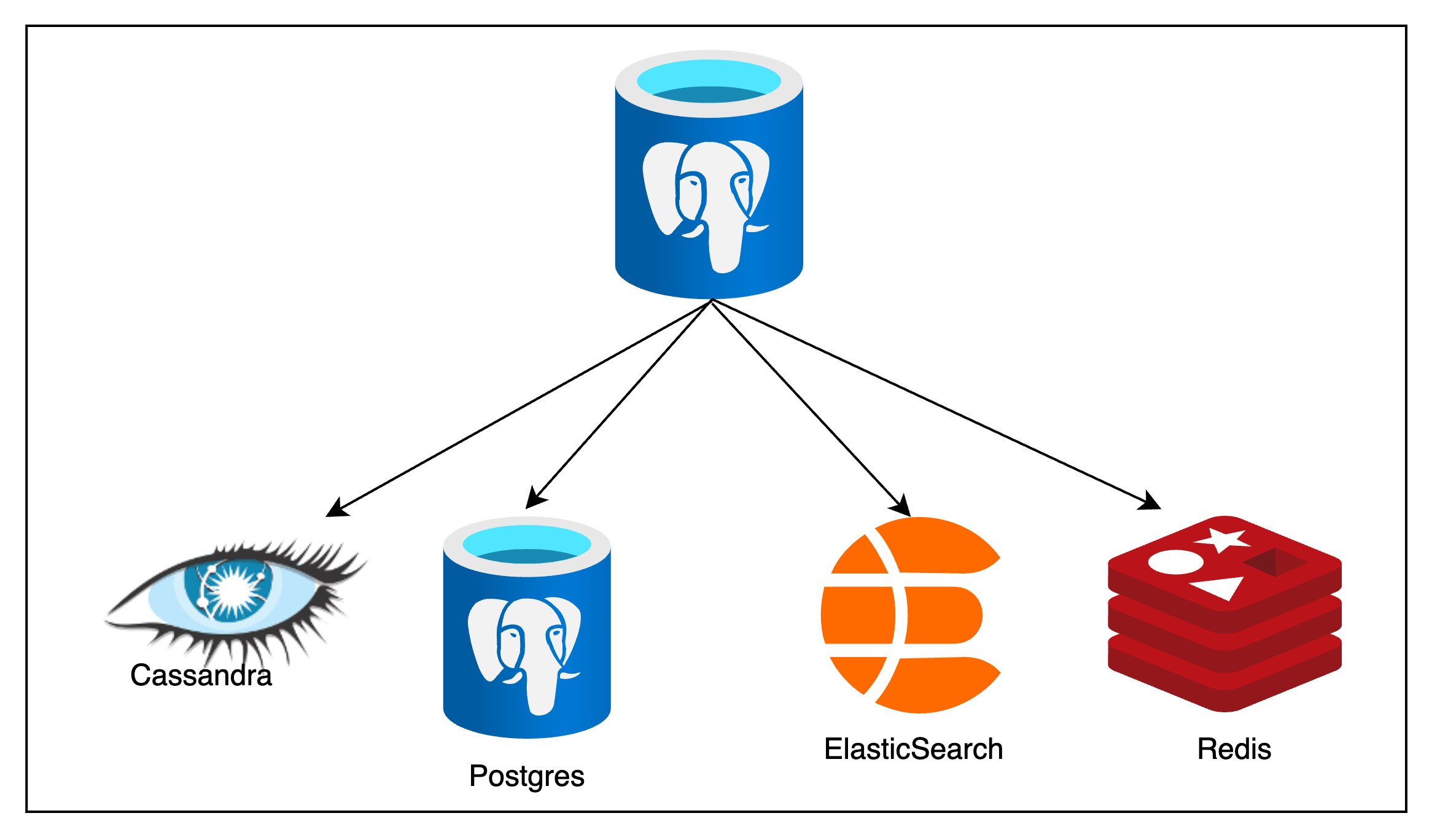
Şekil 3: Birden fazla veritabanına aktarım
Öte yandan çoğu zaman verilerin kaynak veri tabanından birden fazla ve farklı veri tabanlarına aktarımı gerekmektedir. CQRS gibi tasarım desenleri için verilerin ElasticSearch’e aktarılmasına, önbellekleme için Memcached veya Redis’e aktarılmasına, verilerin analizi için bir NoSQL veri tabanı olarak Cassandra veya Couchbase’e aktarılmasına birçok sistemde ihtiyaç duyulmaktadır.
5.2. Dağıtık İşlem (Distributed Transaction) İle Aktarım
Bir diğer yaklaşım; bir mikroservisin birden fazla veri tabanına tek bir işlem(transaction) ile yazması olabilir. Bunun icin XA Transaction (Birden fazla veri tabanına yazma işlemini içeren transaction yönetimi protokolu) kullanılabilir.
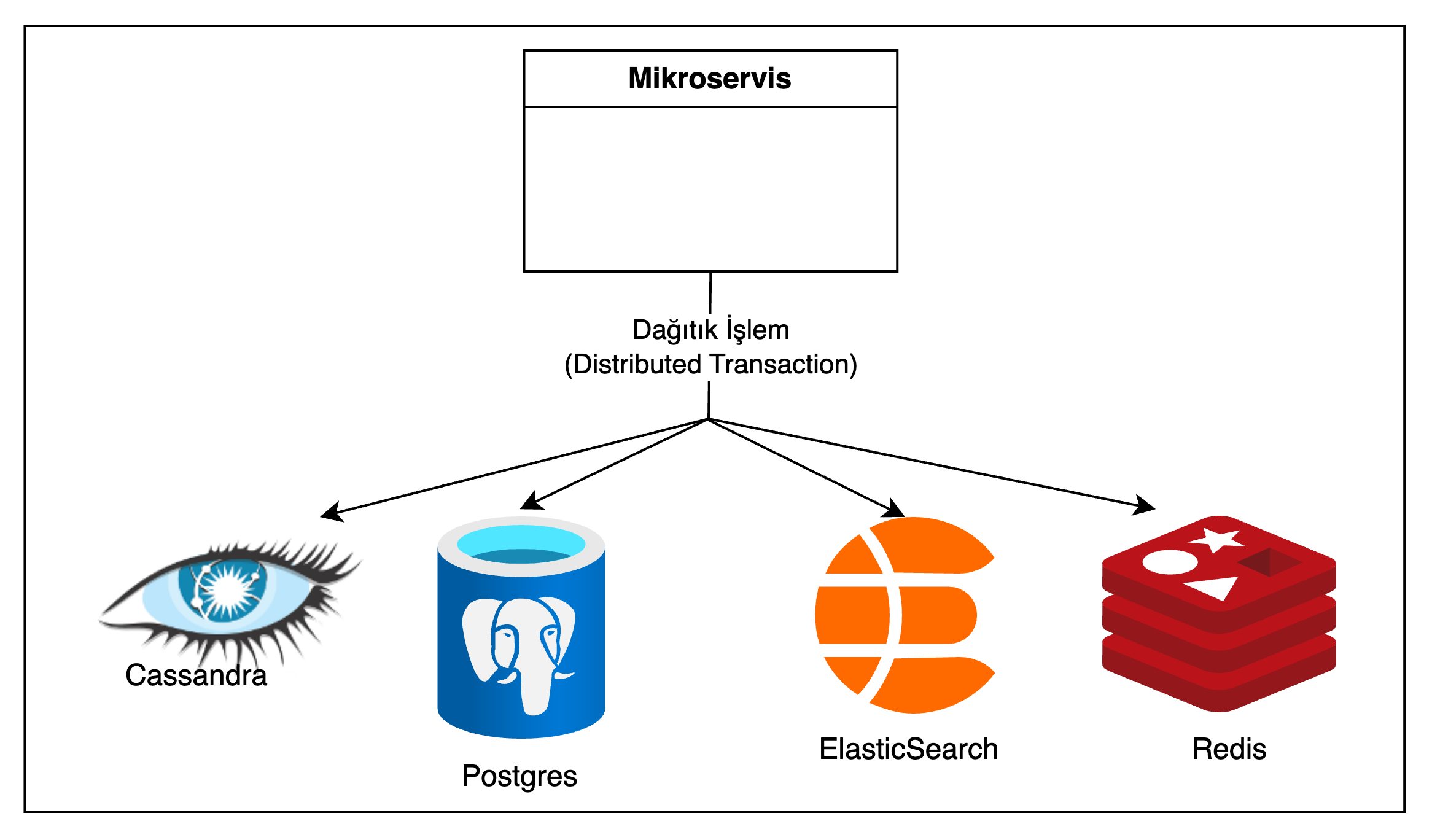
Şekil 4: Dağıtık işlem ile aktarım
Ancak bu yaklaşımın da pek çok dezavantajı vardır:
- Her veri tabanı XA Transaction’ı desteklemez, mesela Elasticsearch,
- XA Transaction’larda hazırlık aşaması bulunur, bu aşamada her veri tabanı commite hazır olduğunu belirtir. Bu aşamada meydana gelebilecek bir hata işleme dahil olan veri tabanlarında kitlenmeye sebep olabilir.
- XA Transactionlarda varsayılan olarak bir deadlock detection(Kaynak Bekleme Kilitlenmesi Algılama) yapisi bulunmaz. Bu da iki transactionın çapraz olarak farklı mikroservislerde birbirlerinin kullandığı kaynakları sonsuza kadar beklemeleriyle yani deadlock(kaynak bekleme kilitlenmesi) ile sonuçlanmasına sebep olabilir.
Bu ve benzeri sebeplerden; birden fazla veri tabanında dağıtık işlem ile veri senkronizasyonu sağlama yaklaşımının çözülmesi zor problemleri bulunmaktadır.
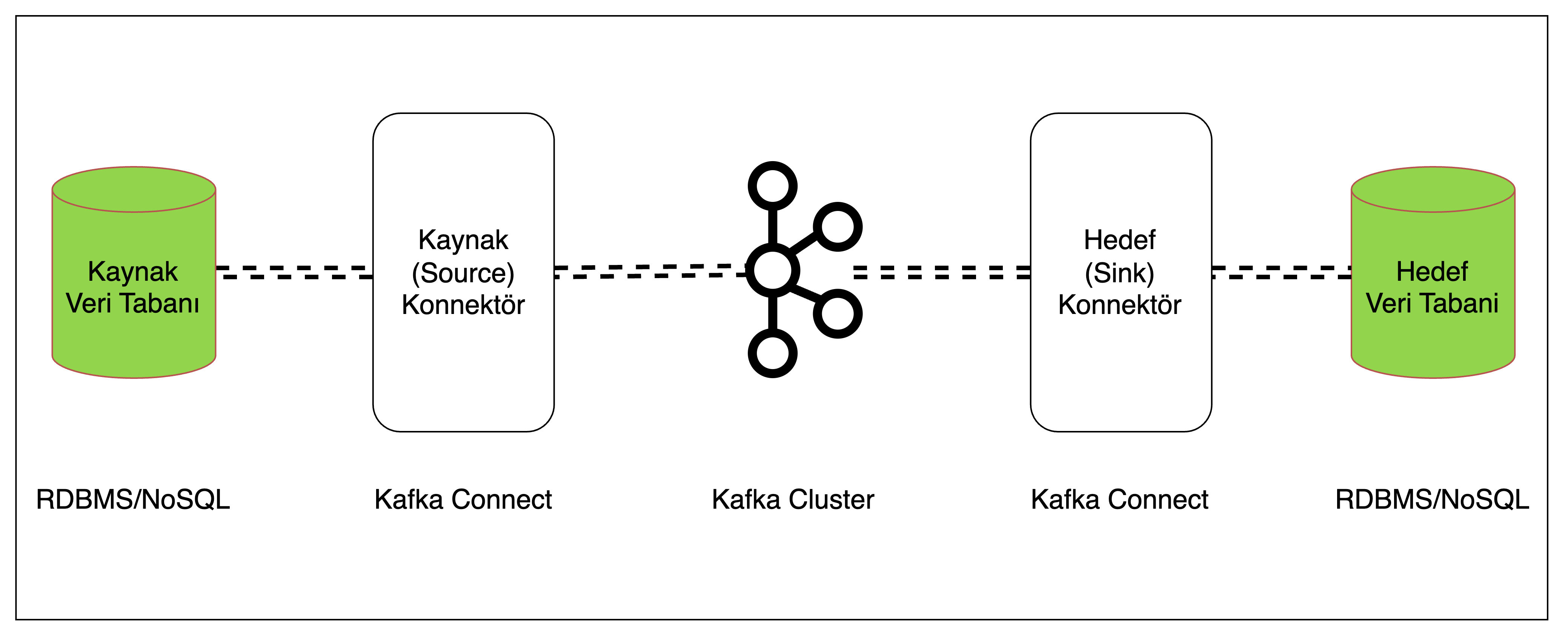
5.3. Kafka Connect ile Aktarım
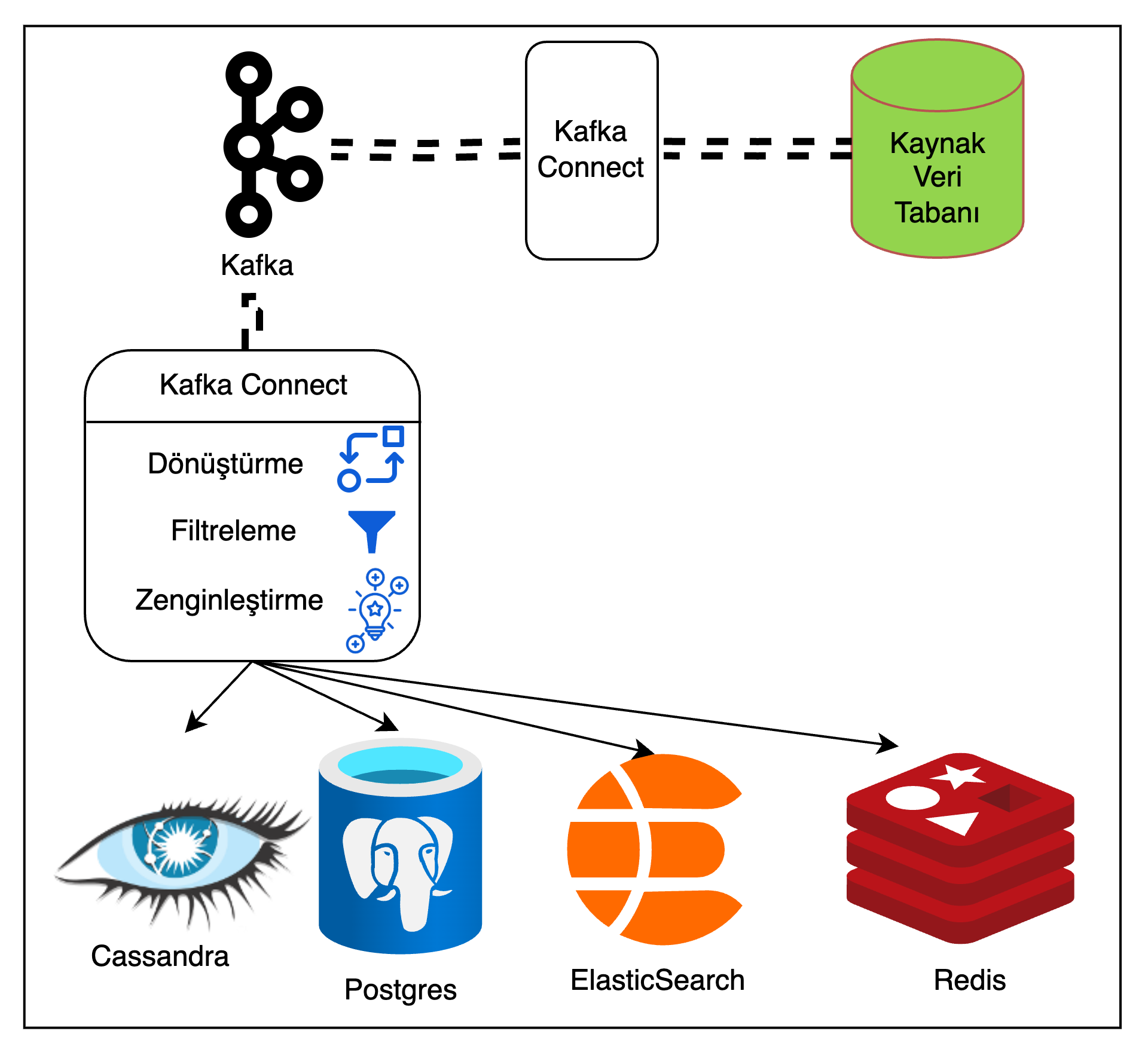
Şekil 5: Kafka Connect ile veri aktarımı
Veri aktarımında Kafka Connect yaklaşımı ise; bir kaynak veri tabanından, veriyi gerçek zamanlı olarak Kafka’ya ve yine Kafka’dan gerçek zamanlı olarak bir hedef veri tabanına aktarmaya olanak tanır. Hem kaynaktan Kafka’ya iletme hem de Kafka’dan hedef veri tabanına iletme sırasında veri dönüştürülebilir, filtrelenebilir ve zenginleştirilebilir.
Veri tabani seviyesinde işlem yapmayı gerektirmediği için veri tabanına ek yük bindirmez. Mikroservis içi dağıtık işlem yaklaşımında olduğu gibi XA Transaction’ın yol açtığı sorunlara veya deadlock’a sebep olmaz.
Bu yaklaşımda veriyi kaynak veri tabanından gerçek zamanlı olarak Kafka’ya aktarmak için izlenen metot Transaction Log Tailing (İşlem Günlüğü Takibi) olarak adlandırılır.
6. Transaction Log Tailing nedir?
6.1. Log Dosyalari
Veri tabanları kendi içlerinde bir hata tolerans mekanizmasi olarak log dosyası kullanırlar.
MySQL için “binlog”, PostgreSQL için “WAL” (Write Ahead Log - Önden Yazma Günlüğü) buna örnektir.
Veri tabanında bir işlem (transaction) içerisinde yollanan değişiklikler önce bu log dosyasına yazılır ve daha sonra veri tabanına işlenir. “WAL_LEVEL” konfigürasyonu varsayılan değer olarak “kopya (replica)”dir ve log dosyasının içeriğinden 3-4 satır ekte görülebilir:
1
2
3
4
rmgr: Btree len (rec/tot): 72/ 72, tx: 744, lsn: 0/0199ED70,
prev 0/0199ED10, desc: INSERT_LEAF off 5, blkref #0: rel 1663/16384/16412 blk 1
rmgr: Transaction len (rec/tot): 34/ 34, tx: 744, lsn: 0/0199EDB8,
prev 0/0199ED70, desc: COMMIT 2024-12-08 16:12:55.476341 UTC
Burada veri tabanı üzerinde gerçekleştirilen işlemler ilgili bilgiler ve işlemle alakalı detayların yazılı olduğunu görebiliriz.
Bu yapı veri tabanı tarafından temelde 3 amaç için kullanılır:
- Crash Recovery (Sistem Çökmesi Sonrası Kurtarma):
- Beklenmedik bir çökme durumunda, veri tabanı log dosyasındaki değişiklikleri tekrar çalıştırarak çökme dolayısıyla zarar görmüş transactionların commit edilmesini, geri alınması(rollback) gerekenlerin ise rollback edilmesini sağlayarak veri tutarlılığını sağlamış olur.
- Point-in-Time Recovery(Anlık Zaman Kurtarma):
- Yukarıdaki içerikte de görülebileceği gibi log dosyaları aynı zamanda commit edilen transactionlar için commit tarihini de göstermektedir, bu da veri tabanında belli bir andaki duruma geri dönme opsiyonu sağlamaktadır.
- Replication and CDC:
- Log dosyaları veri tabanı içeriğindeki veriyi ikinci bir sunucuya kopyalamak veya CDC toollarını beslemek için kullanılabilir.
7. Logical Replication Nedir
Log dosyalarında veri tabanı degisikliklerine ait logların ne kadar kapsamlı olacağı konfigüre edilebilir. Postgres için minimal, replica ve logical olmak üzere 3 mod mevcuttur:
Minimal: Crash Recovery için gerekli minimum bilgilerin yazıldığı moddur.
Replica: Crash Recovery ve Point-In-Time Recovery yapmaya olanak sağlayan default moddur. Aynı zamanda Physical Replication (İki veri tabanını sync etme) için de olanak tanır.
Logical: Replicanın sunduğu tüm özellikleri sunmanın yanında verileri tüm detaylarıyla harici sistemlere aktarabilmek için gerekli ekstra bilgilerin de log dosyasına yazıldığı moddur. Bu modda WAL dosyası üzerinde logical decoding yapılarak satır seviyesi değişiklikler okunabilir formatta alınabilir ve istenilen harici sistemlere aktarılabilir.
Postgres ile Debezium’u kullanabilmek için “wal_level” konfigürasyonunun “logical” yapılması gerekmektedir.
8. Postgres Tablolarında Kopya Kimliği
Kopya Kimliği(Replica Identity) WAL dosyalarına satır seviyesi değişikliklerin ne kadar kapsamlı yazılacağına dair bir konfigürasyondur ve sadece veri tabanının “wal-level” konfigürasyonu “logical” değerindeyken kullanılmaktadır.
Kopya Kimliği için varsayılan “DEFAULT”, dizin kullanarak (USING INDEX), tam (FULL) ve hiç (NOTHING) olmak üzere 4 opsiyon mevcuttur. Tablo seviyesinde bir konfigürasyon olup
ALTER TABLE my_table REPLICA IDENTITY USING INDEX my_unique_index;
komutu ile konfigüre edilir.
NOTHING: Eğer WAL konfigürasyonu “logical” ise ve “Replica Identity” konfigürasyonu “Nothing” ise güncelleme (update) ve silme (delete) işlemleri WAL dosyasına yazılamayacağı için silme ve güncelleme işlemlerine izin vermeyecek ve “
ERROR: cannot update table "your_table" because it does not have a replica identity and publishes updates“
şeklinde hata atacaktır.
8.1. Kopya Kimliği Konfigürasyonları
-
DEFAULT: Varsayılan ayar olup her tablonun replica identity’sini tablonun birincil anahtarını(primary key) kabul eder.
-
USING INDEX: Bir indexin replica identity olarak kullanıldığı ayardır, bu index primary key gibi row özelinde unique olmak zorundadır.
“Default” ve “Using Index” modlarında bir güncelleme işlemi için wal dosyasına yazılan loglar JSON’a çevrildiğinde ekteki çıktı görülür. Verinin güncelleme işleminden önceki haline dair yazılan tek bilgi ilgili verinin Replica Identity’si olan ID’sidir.
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"payload": {
"before": { "id": 1001 },
"after": {
"id": 1001,
"item_name": "random name",
"total_count": "2"
},
"op": "u",
"ts_ms": 1716575453417,
"transaction": null
}
}
Kopya Kimliği konfigürasyonu “full” yapıldığında ise güncelleme işleminin önceki haline dair yazılan bilgi içerisinde verinin tüm sütunları mevcuttur.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"payload": {
"before": {
"id": 1001,
"item_name": "random name",
"total_count": "1",
},
"after": {
"id": 1001,
"item_name": "random name",
"total_count": "2",
},
"op": "u",
"ts_ms": 1716575453417,
"transaction": null
}
}
8.2. Ara Tablolarda Kopya Kimliği
Kopya kimliğinin “full” yapılması gereken bir diğer senaryo ise çoğunlukla çoktan çoka(Many To Many) ilişkilerde kullanılan ara tablolardır. Bu tablolar çoğunlukla ID sütunu bulundurmaz ve amaçları iki tablo arasındaki verilerin ilişkisini saklamak olur. Herhangi bir birincil anahtarı bulunmadığı içinse kopya kimliğinin “full” yapılmasını gerektirir. Örnek bir ara tablo yapısı ekte görülebilir:
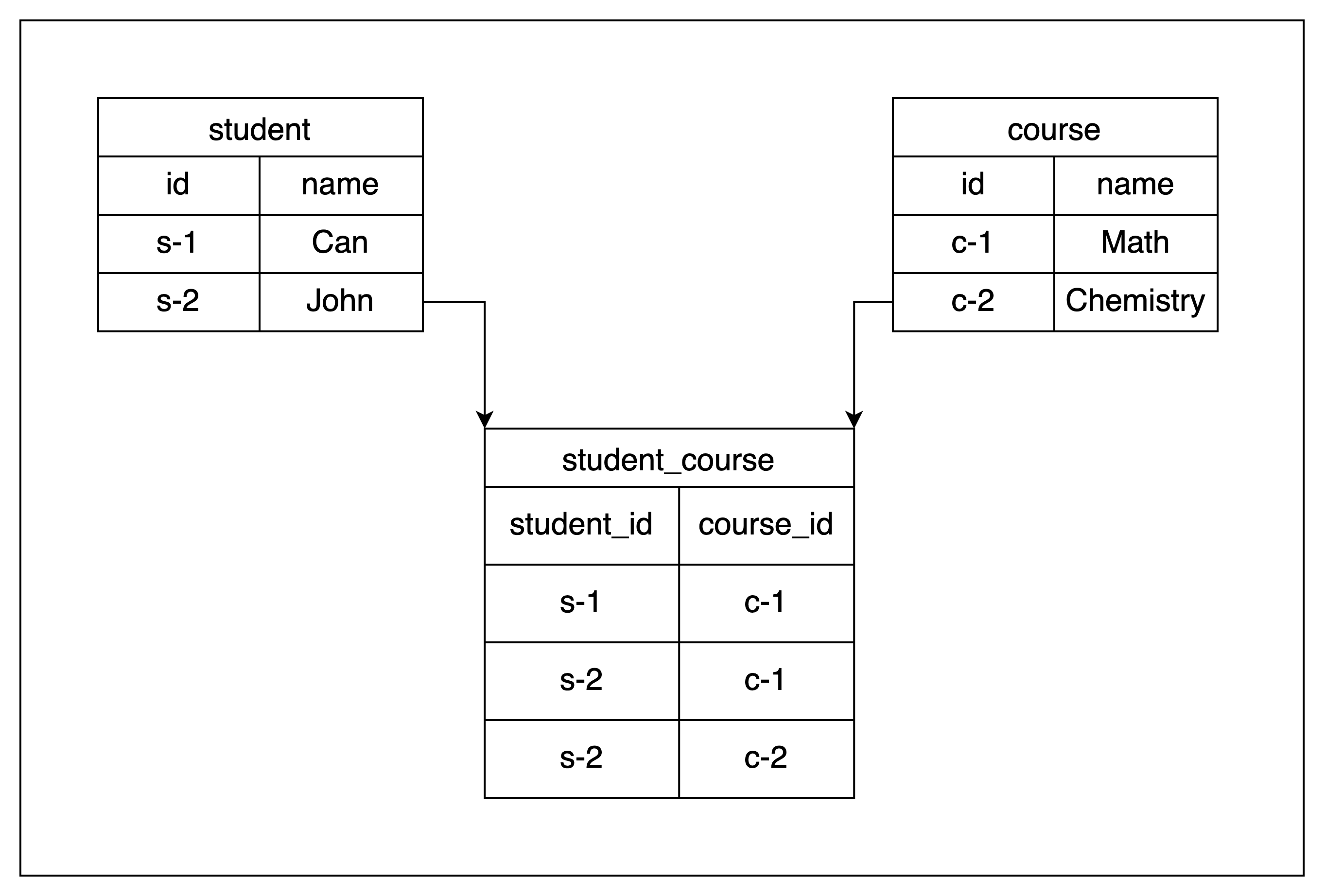
Şekil 6: Örnek ara tablo yapısı
Kopya kimliğini “full” yapmak güncelleme ve silme işlemlerinde log dosyalarına yazılan veri miktarını artırdığından disk kullanımını, ve slotlar aracılığıyla değişikliği yayınlama işleminde akan veriyi artıracağından CPU kullanımını önemsenmeyecek kadar ufak da olsa artıracaktır.
9. Transaction Log Tailing Akış Şeması ve Yayınlama
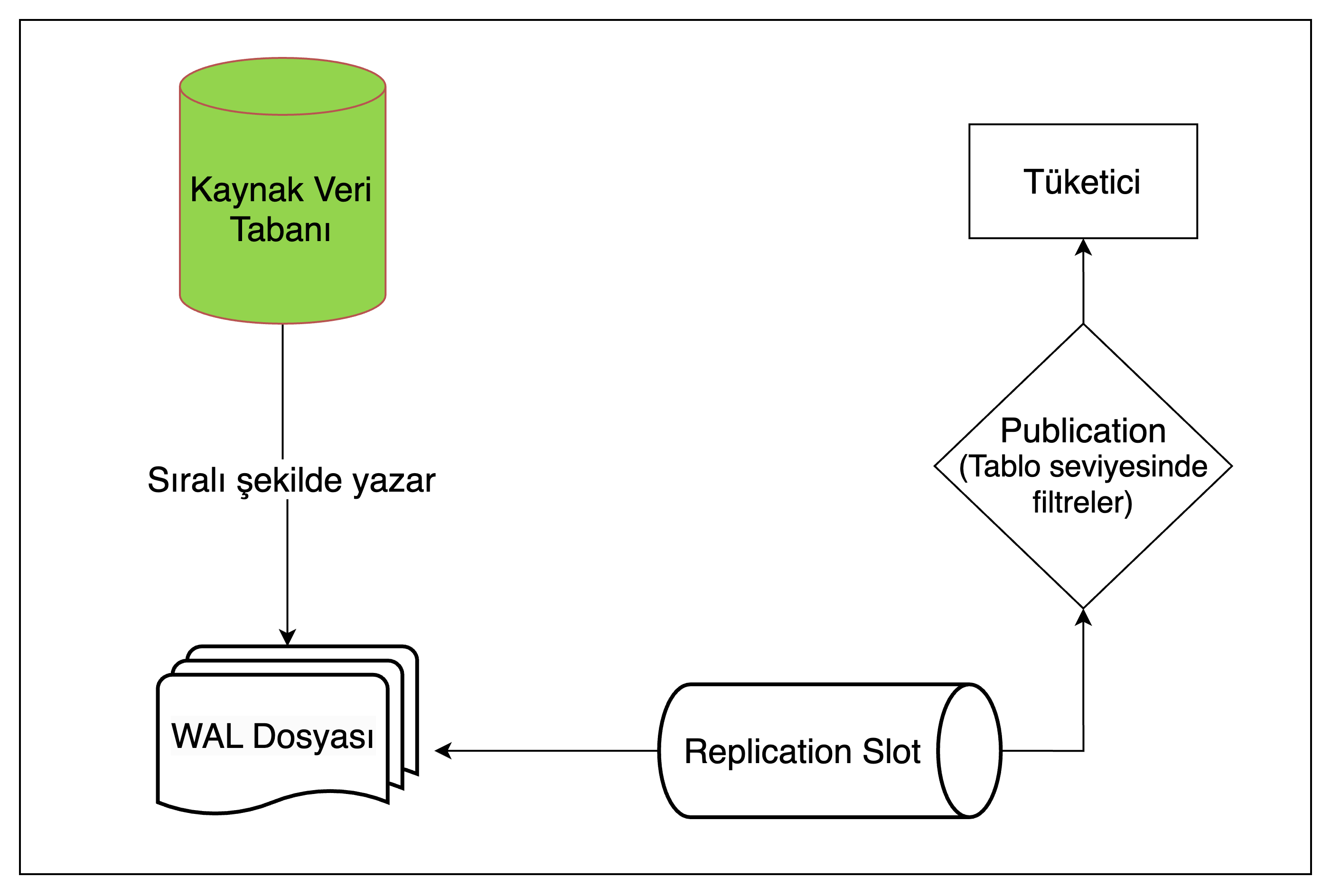
Şekil 7: Transaction Log Tailing akış şeması
1 - WAL seviyesi ve kopya kimliği, wal dosyalarına yazılan verinin ne kadar kapsamlı olacağını belirtir. Bu ayarlara göre değişiklikler sıralı olarak WAL dosyalarına yazılır.
2- Replication Slot(Çoğaltma Yuvası) WAL dosyalarından değişikliği okur. Birden fazla slot olabilir ve her slot en son hangi satırı okuduğu gibi detayları kendi içerisinde tutar.
3- Yayınlama (publication) hangi tablolardaki değişikliklerin tüketicilere (consumer) iletileceğini belirten konfigürasyondur.
1
CREATE PUBLICATION publication_name FOR TABLE table_name [<tablo_ismi>];
Komutu ile bir publication oluşturulur, ve hangi tabloları içereceği belirtilir. WAL dosyasından okunan değişiklik ancak değişikliğin ait olduğu tablo bir publication ile ilişkiliyse consumer’lara iletilir. Debezium kullanırken bu işlemi manuel yapmak gerekmez, debezium otomatik olarak ihtiyaç duyulan yapıları veri tabanında oluşturacaktır.
10. Bağlayıcı Konfigürasyonları
Debezium’da bir bağlayıcı “debezium_host/connectors” adresine ekteki gibi bağlayıcı konfigürasyonlarını da içeren bir http post isteği atılmasıyla oluşturulur.
1
2
3
4
5
6
7
8
{
"name": "ornek-source-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"plugin.name": "pgoutput",
"database.hostname": "postgres"
}
}
Bu konfigürasyonlar bağlayıcının ihtiyaca göre şekillendirilmesini sağlar, ekte sık kullanılan konifügrasyonlar, bu konifügrasyonların varsayılan değerleri ve işlevleri görülmektedir:
| Property | Default | Description |
|---|---|---|
| connector class | - | Bağlayıcı için Java sınıfının ismi;postgres için bu değer her zaman io.debezium.connector.postgresql.PostgresConnector olmalıdır. |
| name | - | Bağlayıcı ismi, aynı isimle 2 bağlayıcı oluşturulamayacaktır. |
| plugin.name | decoderbufs | WAL dosyasındaki değişiklikleri decode etmek için kullanılacak eklenti; decoderbufs veya pgoutput değerlerini alabilir. |
| topic.prefix | - | Bağlayıcının değişikliği paylaştığı kafka topic isimlerinin tamamında ön ek olarak kullanılacak isim. |
| table.include.list | - | Bağlayıcının değişiklikleri izlemesi istenilen veri tabanı tablolarının isimlerinin listesi. Virgülle ayrılmış halde “şemaİsmi.tabloİsmi” formatinda belirtilmelidir. Bu konfigürasyon kullanıldığında table.exclude.list konfigürasyonu kullanılmamalıdır. |
Debezium için birçok konfigürasyon opsiyonu olsa da ekte görülenlerin bunlardan en kritikleri oldukları söylenebilir.
10.1. Anlık Görüntü (İnitial Snapshot - snapshot.mode) Konfigürasyonu
Debezium’un, bağlayıcı başladığında izlenilen tablonun mevcut halinin yakalanıp yakalanmayacağını belirtir. Burada önemli bir nokta; anlık görüntünün WAL dosyasından değil doğrudan veri tabanındaki tablodan alındığıdır. Bunun sebebi WAL dosyalarının belirli bir süre sonra siliniyor olup ilk andan itibaren tüm değişikliklerin WAL dosyasından okunmasının mümkün olmamasıdır. Anlık görüntü sonrasında ise tabloya dair değişiklikler WAL dosyasından okunur ve normal akış devam eder. Bu konfigürasyon için ekteki opsiyonlar mevcuttur:
- Always: Bağlayıcı her basladiginda anlık görüntü (snapshot) alır. Anlık görüntüden sonra bağlayıcı sonraki değişiklikleri izlemeye devam eder.
- Initial: Bağlayıcı sadece bir tablo için konum (offset) bulunmuyorsa anlık görüntü alır.
- Initial Only: Bağlayıcı anlık görüntü alır ve durur, sonrasında gelen değişiklikleri izlemez. Default degeri initial’dir.
Ekte görülebileceği gibi initial snapshot sırasında Kafka’ya gönderilen mesajların işlem tipi “r”’dir. Bu da initial snapshot sırasında gönderilen mesajların diğerlerinden ayrımının yapılabilmesini ve bu mesajlar için custom logic işletilebilmesini olanaklı kılar.
1
2
3
4
5
6
7
8
9
10
11
{
"before": null,
"after": {
"id": "351af71a-f31f-440e-9753-8b7a51a6b555",
...
},
"source": {
...
},
"op": "r"
}
10.2. Kalp Atışı (Hearbeat - heartbeat.interval.ms) Konfigürasyonu
Kafka’nın beklenmedik şekilde çökmesi durumu Debezium için bir sorun yaratmaz, Kafka tekrar çalıştığında Debezium değişiklikleri okuyup kafkaya göndermeye devam eder. Debezium’un çökmesi de bir sorun yaratmaz, Debezium; değişiklikleri okumaya devam etmesi gereken sıra bilgisini tuttuğu Kafka topicinden alarak değişiklikleri okumaya ve Kafka’ya göndermeye devam eder.
Ancak veri tabanının çökmesini veya Debezium’un veri tabanından değişiklikleri okumasını engelleyecek altyapı seviyesindeki hataları debezium algılayamaz, Debezium’un veri tabanındaki değişiklikleri okumaya devam ettiğini anlayabilmek için bu konfigürasyona ihtiyaç duyulur.
Bu özellik varsayılan olarak kapalıdır ve ekte görülebildiği gibi milisaniye cinsinde sayısal bir değerle konfigüre edilir, Debezium veri tabanındaki değişiklikleri sağlıklı şekilde okuyorsa verilen aralıkta Kafka’ya zaman bilgisi(timestamp) içeren bir mesaj gönderir. Bu timestamp’ten kalp atışının (heartbeat) atıldığı tarih anlaşılabilir.
1
"heartbeat.interval.ms": 1000
Kafkaya mesajlari gönderdiği topic ismi __debezium-heartbeat-{db.name} formatındadir.
10.2.1. WAL Dosyası Şişmesi Sorunu Ve Heartbeat
Bölüm 9’da Debezium’un Postgresql’e bağlandığında bir mantıksal çoğaltma yuvası oluşturduğu belirtilmişti. Postgres; bu slotla ilişkilendirilmiş WAL kayıtlarını, Debezium bu kayıtları işleyip doğrulama gönderene kadar saklar. Eğer Debezium, izlediği tablolar üzerinde hiçbir değişiklik yakalamazsa o slot için LSN(Log Sequence Number - Günlük Sıra Numarası) ilerlemediğinden, PostgreSQL bu WAL segmentlerini silemez ve gereksiz yere saklamaya devam eder.
PostgreSQL’de tüm veritabanları ortak bir WAL dosyasını kullanır. Dolayısıyla, Debezium’un dinlediği veritabanında uzun süre hiç değişiklik olmazken, başka bir veritabanında yüksek trafik devam ediyor olabilir, böyle bir senaryoda Debezium’un oluşturmuş olduğu slotta LSN ilerlemediğinden WAL dosyaları silinemeyecek ve boyut olarak şişmeye başlayacaktır. Benzer şekilde, Debezium’un bağlı olduğu veritabanında değişiklikler olsa bile Debezium’un izlediği tablolar güncellenmiyorsa Debezium yeni bir event üretmez; bu yüzden çoğaltma yuvası doğrulama göndermez ve PostgreSQL de eski WAL kayıtlarını tutmaya devam eder.
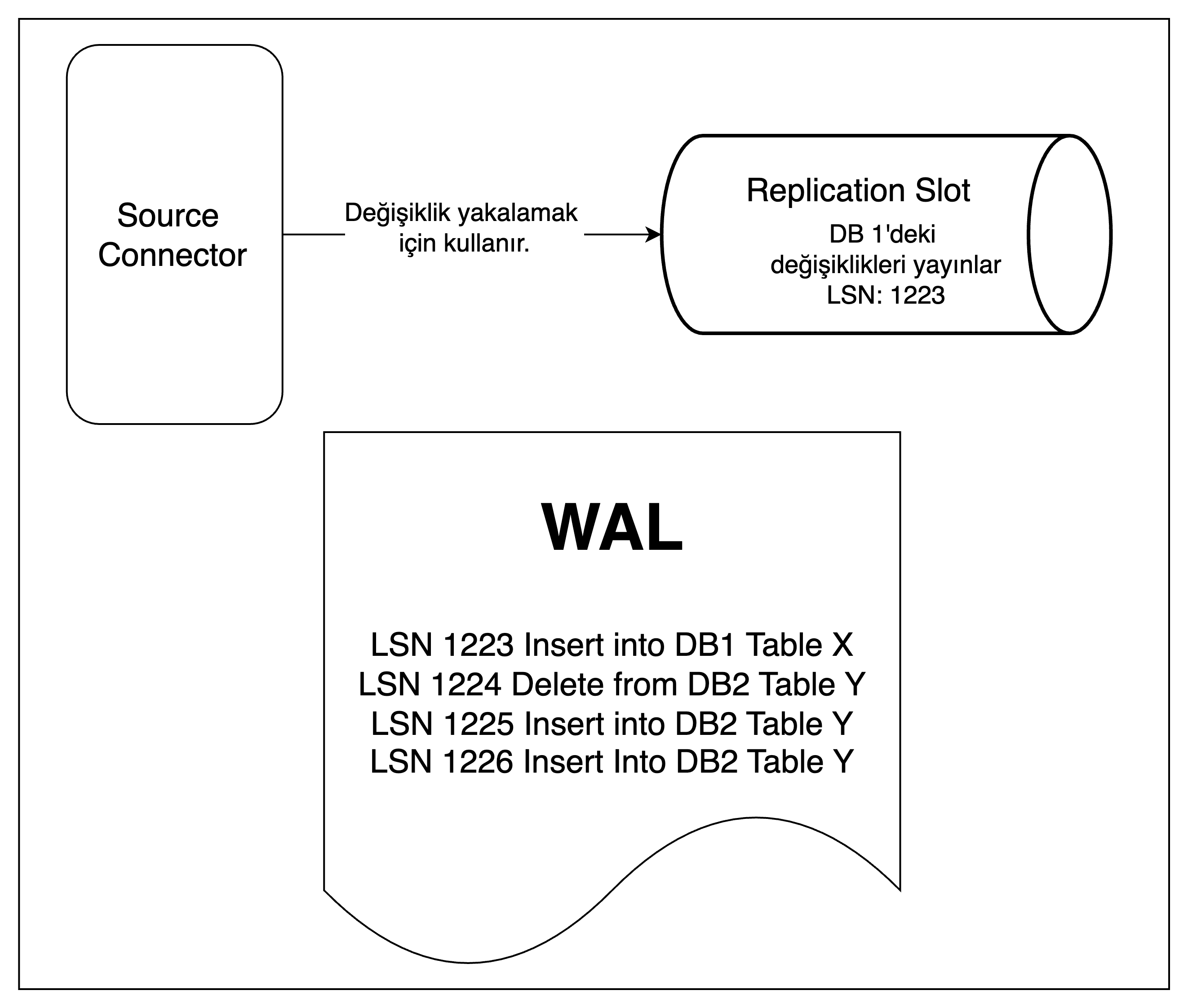
Şekil 8: WAL işleme mekanizması
Örnek bir senaryo Sekil 8’de görülebilir. Senaryoda; Debezium, 1 numaralı veri tabanında Tablo X’deki değişiklikleri izlemek için konfigüre edilmiş durumda, oluşturmuş olduğu çoğaltma yuvası da sadece Tablo X’deki değişiklikleri yayınlıyor harici değişiklikleri filtreliyor ve içerisinde LSN olarak 1223 numarasını tutuyor. Bu sırada 2 numarali veri tabanında Tablo Y’de daha yüksek bir trafik var ve WAL dosyasını dolduruyor, 1 numarali veri tabanında yeni değişiklik olmadığı icin çoğaltma yuvası içerisindeki LSN ilerlemiyor.
Böyle bir senaryoda 1223 numaralı Log Sequence’dan itibaren WAL dosyası silinemeyecek ve WAL dosyası zamanla şişecektir.
10.2.2. WAL Dosyası Şişmesi Çözümü ve Heartbeat Action Query
Bu sorunu çözmek için Debezium’un heartbeat mekanizması kullanılabilir.
Önceki başlık - Örnek senaryoda 1 numaralı veri tabanındaki değişiklikleri izleyen bir çoğaltma yuvası için LSN sorgulandığında ekteki çıktı alınır:
1
2
3
4
slot_name | restart_lsn | confirmed_flush_lsn
-----------+-------------+---------------------
debezium | 0/19A8040 | 0/19A8570
Burada “restart_lsn” çoğaltma yuvası hangi noktadan itibaren WAL dosyasının içeriğine ihtiyaç duyduğunu belirttiği sıra numarasıdır. Veri tabanı eski kalmış WAL dosyalarını temizlerken bu sıra numarasına bakacak ve bu ilerlemediği takdirde o noktadan itibaren wal dosyalarını temizlemeyecektir.
WAL dosyasının son iki satırı ise ekteki gibidir:
lsn: 0/019A85A8, prev 0/019A8570, desc: RUNNING_XACTS nextXid 751
lsn: 0/019A8570, prev 0/019A8540, desc: RUNNING_XACTS nextXid 751
2 numaralı veri tabanında (çoğaltma yuvası tarafından izlenmeyen) bir değişiklik yaptıktan sonra WAL dosyası ekteki gibidir:
lsn: 0/019A85A8, prev 0/019A8570, desc: RUNNING_XACTS nextXid 751
lsn: 0/019A8570, prev 0/019A8540, desc: RUNNING_XACTS nextXid 751
lsn: 0/019A85A8, prev 0/019A8570, desc: RUNNING_XACTS nextXid 751
1 numaralı veri tabanını izleyen çoğaltma yuvası için LSN sorgulandığında alınan çıktı yine ekteki gibidir:
1
2
3
4
slot_name | restart_lsn | confirmed_flush_lsn
-----------+-------------+---------------------
debezium | 0/19A8040 | 0/19A8570
Görülebileceği üzere WAL dosyasındaki değişiklik çoğaltma yuvasının izlediği veri tabanı üzerinde olmadığından çoğaltma yuvası için LSN ilerlemedi.
Bu noktada heartbeat mekanizmasi “heartbeat.action.query” konfigürasyonu ile kullanılarak sorun çözülebilir. 1 numaralı veri tabanı üzerinde bir heartbeat tablosu oluşturulur. ”heartbeat.action.query” konfigürasyonuna “INSERT INTO heartbeat_table (text) VALUES (‘heartbeat’)” benzeri bir insert sorgusu(query) verilir. Bu sayede bağlayıcı tarafından kafkaya her heartbeat gönderildiğinde ilgili query de WAL dosyasına ufak bir insert querysi yazacak böylece kendisi icin LSN değerini de sürekli olarak güncel tutacak ve postgresin WAL temizliği yapmasını engelleme sorununu çözmüş olacaktır.
11. Topic Konfigürasyonları
11.1. Log Compaction (Kayıt Sıkıştırma)
Kafka’da geleneksel veri muhafaza (Log Retention) yaklaşımı eski mesajların belli bir boyuta ulaştığında veya üzerinden belli bir süre geçtikten sonra silinmesi üzerine kuruludur.
Log Compaction ise her anahtar için en azından bir değerin saklı tutulması yaklaşımdır. Bu değer o anahtar ile ilişkilendirilmiş son değerdir. Bu da bir topicteki bir anahtar için eski değerler silinmiş olsa bile son versiyonunun saklı tutulacağı, istenildiğinde son halinin anlık görüntüsünün(Snapshot) alınabileceği anlamına gelir. Bu yaklaşım bir veri tabanı için değişiklikleri tutan veya olay kaynaklı olan yani durum bilgisi saklayan (stateful) topicler için kullanışlıdır.
Kafka’da bir topic için compact policy ekteki konfigürasyonla etkinleştirilebilir.
1
"log.cleanup.policy": "compact"
Log Compaction Örneği:
| Key | Value | Offset |
|---|---|---|
| A | X | 1 |
| B | Y | 2 |
| A | Z | 3 |
| C | W | 4 |
Log Compaction Sonrası:
| Key | Value | Offset |
|---|---|---|
| B | Y | 2 |
| A | Z | 3 |
| C | W | 4 |
Örnekte A anahtarı için X değerinin eski, Z değerinin ise yeni olduğu görülüyor.
Hangi değerin daha yeni olduğuna offset değerinden karar veriliyor.
- Log Compaction Kafka tarafından anlık olarak değil asenkron olarak gerçeklestirilir.
- Log Compaction sırasında bir tombstone eventle karşılaşınırsa bir süre sonra tombstone event de dahil olmak üzere o anahtar ile ilişkilendirilmiş tüm değerler silinecektir. Bu da stateful topic’ler icin çoğu zaman istenmeyen bir durumdur.
11.2. Tombstone Mesajlar
Tombstone mesajlar anahtar’ı bulunan ancak değeri bulunmayan özel mesajlardir. Kafka, Log Compaction sirasinda bir ölü(tombstone) mesaj ile karşılaştığında tombstone mesaj da dahil olmak üzere, tombstone mesajını taşıdığı mesaj anahtarı ile aynı anahtarı taşıyan tüm mesajları siler. Tombstone mesajlar; taşıdığı anahtara sahip varlığın sistemden tamamen kaldırıldığı anlamını taşır.
Debezium; veri tabanında bir silme işlemi sonrası Kafka’ya bir silme mesajı gönderir. Silme mesajı sonrası bir de “tombstone” mesajının gönderilip gönderilmeyeceği ekteki konfigürasyonla belirtilir:
1
"tombstones.on.delete": "true"
Bu konfigürasyon değeri “true” olduğu takdirde ekteki gibi bir silme mesajı sonrası:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Key: {
"id": "40903df2-7662-475b-986d-e06bcb26dd98"
},
Value: {
"before": {
"id": "40903df2-7662-475b-986d-e06bcb26dd98",
...
},
"after": null,
"source": {
...
},
"op": "d",
...
}
bir de tombstone mesajı görülecektir:
1
2
3
4
5
6
Key: {
"id": "40903df2-7662-475b-986d-e06bcb26dd98"
},
Value: {
}
- Tombstone eventler ilgili anahtara ait tüm mesajları sildiğinden, sistemi denetlemesi sırasında olan bitenin anlaşılmasını zorlaştırır.
- Verilerin kafka’dan bir veri tabanına kaydı sırasında hataya sebep olur.
- Silme işlemi içerisindeki “before” gibi detay bilgilerin kaybolmasına sebep olur.
Bu nedenlerle stateful topic’lerde tombstone eventler çoğunlukla tercih edilmez.
12. Debezium İçsel Topicleri
Debezium’un kendi iç sistemiyle ilgili bilgileri tuttuğu birkaç topic bulunur.
12.1. Konum (Offset) Topic
Son işlenen değişikliğin sıra numarası (LSN) bilgisini tutar. Bağlayıcı yeniden başladığında bu topic içerisinden son okumuş olduğu mesajın sıra numarasını bularak kaldığı yerden değişiklikleri okumaya devam eder. Bu topic’in silinmesi durumunda mevcut change eventlerin en baştan tekrar okunması gerekecektir.
PostgreSQL icin offset topic’indeki bir mesaj ekte görülebilir.
1
2
3
4
5
{
"lsn": 26622464,
"txId": 738,
"ts_usec": 1739753371071173
}
12.2. Config Topic
Debezium’un bağlayıcı konfigürasyonlarını tuttuğu topictir, silindiği takdirde manuel şekilde yeniden oluşturulması gerekir. Bu topic’den örnek mesajlar ekte görülebilir:
1
2
3
4
5
6
Key: session-key,
Value: {
"key": "4Q0C22pQLfHNdexC1sQnRNG5BxUE4IWtik13Q4MA5rw=",
"algorithm": "HmacSHA256",
"creation-timestamp": 1739756131876
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Key: connector-siparis_source_connector,
Value: {
"properties": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"plugin.name": "pgoutput",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "q",
"database.dbname": "db_name",
"database.server.name": "dbserver1",
"table.include.list": "public.table_name",
"topic.prefix": "siparis",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"heartbeat.interval.ms": "1000",
"status.storage.topic": "connect-status",
"name": "siparis_source_connector"
}
}
12.3. Durum (Status) Topic’i
Bağlayıcılarin durumunu tuttuğu topictir, bağlayıcı durumunu takip etmek için kullanılabilir.
Status topicinden bir örnek mesaj ekte görülebilir:
1
2
3
4
5
6
{
"state": "RUNNING",
"trace": null,
"worker_id": "192.168.97.5:8083",
"generation": 3
}
13. Single Message Transform (Mesaj Dönüştürme)
Kaynak veri tabanından Kafka’ya veya Kafka’dan hedef veri tabanına veri gönderilen verileri manipüle etmek gerekebilir. Kaynaktan gelen veriler her zaman hedef sistemin istediği formatta olmayabilir; alan isimlerini değiştirmek, veriyi filtrelemek ya da ek bilgi eklemek gerekebilir. Kafka Connect’te bu ihtiyacı karşılamak için Single Message Transformation (SMT) adı verilen yapı ortaya çıkmıştır.
Single Message Transformation (SMT) veri akışında mesajları dönüştürmeye veya yönlendirmeye olanak sağlar. Bu dönüşümler büyük bir işlem gücü gerektirmez. Debezium; Kafka Connect uzerine insa edildiği için SMT’leri destekler.
SMT, her bir mesajı tek tek işler ve bu mesajlar üzerinde tanımlı kurallar doğrultusunda dönüştürme işlemleri uygular. Bu dönüşümler genellikle şunları içerir:
- Alan Ekleme veya Çıkarma: Mesaj içindeki gereksiz alanların filtrelenmesi veya yeni alanların eklenmesi.
- Veri Formatını Değiştirme: Tarih formatını değiştirilmesi, bir alanın veri tipinin dönüştürülmesi vb.
- Mesajları Yönlendirme: Mesajları farklı Kafka topic’lerine yönlendirmek.
13.1. Örnek kullanım: Route Transformasyonu
Debezium; varsayılan olarak veri tabanında bir tablodan yakaladığı değişiklikleri, Kafka’da aynı tablo ismiyle açmış olduğu topic’e iletir. Fakat zaman zaman verilerin farklı bir topic’e yönlendirilmesi gerekebilir. Bu durumda route transformation’dan faydalınabilir.
Bunun icin gerekli konfigürasyonlar ekteki gibi gecilir:
1
2
3
4
"transforms": "route",
"transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.route.regex": "db.schema.topic1",
"transforms.route.replacement": "topic2"
”transforms” kulalnılacak transformasyonu ”transforms.route.type” kullanılacak Kafka Connect pluginini (Aslında Java ile yazılmış bir sınıf ismine tekabül etmektedir.); ”transforms.route.regex” yönlendirmede kullanılan kaynak topic ismini ”transform.route.replacement” ise yönlendirmede kullanılacak hedef topic ismini belirtmektedir.
Bu konfigürasyondan sonra Debezium’un “topic1”den yakaladığı tüm değişiklikler doğrudan “topic2”e iletilecektir.
13.2. Sık Kullanılan Transformasyonlar
13.2.1. Cast (Tip Dönüştürme)
Bir mesajın belirli alanlarını veya tamamını farklı bir veri tipine dönüştürmek için kullanılır. Bir sayısal alanın veri tipi “Integer” yerine daha küçük boyutlu olan “Short” tipine çevrilebilir. Veriyi hedef sistemin gereksinimlerine uygun hale getirmek veya veri boyutunu optimize etmek için kullanışlıdır.
13.2.2. ExtractField (Alan Çıkarma)
Yakalanan bir degisiklikte belirli bir alanı seçip diğer tüm alanları bırakır. Örneğin, bir JSON veri yapısında yalnızca “id” alanı alınıp diğer tüm alanlar yok sayılabilir.
13.2.3. Flatten (Yapıyı Düzleştirme)
İç içe geçmiş (nested) veri yapılarındaki alanları düz(flat) bir formata çevirir.
Transform oncesi veri:
1
{ "company": { "name": "TUBITAK", "number": (0312) 289 92 22 } }
Transform sonrasi veri:
1
{ "company.name": "TUBITAK", "company.number": "(0312) 289 92 22" }
Örnekteki gibi iç içe objeler barındıran bir JSON objesi, düz hale getirilebilir.
14. Özel Transformasyonlar
”Örnek Kullanım - Route Transformation” ve “Sık Kullanılan Transformasyonlar” başlıklarında değinilmiş olan SMT’ler kafka-connect ile built-int (gömülü) olarak gelen SMT’lerdi. Ancak Kafka-Connect özel SMT’lere de olanak sunuyor. Bunun için custom SMT 0’dan yazılabilir veya 3. parti olarak bulunup kullanilabilinir.
Bunun icin özel SMT’nin JAR halinde debezium konteyneri içerisinde “/kafka/connect/plugins” dizinine atılması gerekir. Hali hazırda birçok özel SMT 3. parti olarak bulunmakta ve doğrudan kullanilabilmektedir.
Üçüncü parti olarak bircok SMT halihazirda bulunabilse de belli senaryolar icin ozellesmis SMTlere ihtiyac duyulabilir. Bu tarz bir dumuda sifirdan bir SMT kolayca yazilabilmekte ve kullanilir hale getirilebilmektedir.
15. Kafka’da Eş Güdümlülük (İdempotency)
Kafka’da bir mesajın bir kere consume edildiğinden emin olmak için Consumer seviyesinde idempotency’e(eş güdümlülük) ihtiyaç duyulur. Kafka varsayılan olarak bu desteği sunmaz ve idempotency icin ek gerçekleştirmeler yapmak gerekir. Bu gerçekleştirmelerden yaygın olan bir tanesi; veri tabanindaki bir tabloya consume edilen mesajların kaydedilmesi yaklaşımıdır. Bunun için mesajlarin unique birer ID’ye sahip olması gerekir ve bir mesaj tüketilmeden önce; veri tabanından daha önce tüketilip tüketilmediği kontrol edilir ve ancak daha önce tüketilmemişse tüketilir.
15.1. Eş Güdümlü Tüketici Oluşturmak İçin Özel Transformasyon
Varsayılan olarak Debezium’un Kafka’ya gönderdiği mesajların başlığında ID alanı bulunmaz, bunun için SMT yardımıyla mesajlara unique ID’ler eklenebilir. Bu işlem için 3. parti bir SMT, JAR halinde eklenebileceği gibi bu SMT manuel de gerçekleştirilebilir. Ekte bu SMT gerçekleştirilmesinin nasıl yapılacağı adım adım görülmektedir:
Adım 1 - Kafka mesajında değişiklik yapmaya olanak sağlayan “Transformation” arayüzü gerçekleştirilir.
1
2
3
4
public class InsertUuid<R extends ConnectRecord<R>> implements Transformation<R> {
...
}
Bu arayüzün gerçekleştirilmesini beklediği metodlardan kritik olanları ekteki gibidir:
- configure: Bağlayıcı konfigürasyonuna girilen değerlerin “Map” tipinde iletildiği metottur.
- apply: Üretilen her mesajın uğradığı ve trasformasyonun yapıldığı metottur.
- close: Bağlayıcının durdurulması aşamasında çalışan; genelde kaynakların kapatılmasi için kullanılan metottur.
Adım 2 - Bağlayıcı için belirtilmesi beklenilen konfigürasyonlar “CONFIG_DEF” değişkeniyle tanımlanır. Bağlayıcı çalıştığında, Kafka Connect tüm konfigürasyonları “configure” metoduna parametre olarak geçer, tanımlanmış olan “CONFIG_DEF” ve parametre olarak gelen konfigürasyonlar kullanılarak bir “SimpleConfig” oluşturulur. Bu a;amada eğer kullanıcı beklenilen konfigürasyonlardan herhangi birini belirtmemiş veya hatalı belirtmiş ise exception ile karşılaşacak ve bağlayıcı çalışmayacaktır.
1
2
3
4
5
6
7
8
9
10
11
12
13
public static final String UUID_FIELD_NAME = "uuid.field.name";
public static final ConfigDef CONFIG_DEF = new ConfigDef()
.define(UUID_FIELD_NAME, ConfigDef.Type.STRING, "uuid", ConfigDef.Importance.HIGH,
"UUID Field name");
private String fieldName;
@Override
public void configure(Map<String, ?> props) {
final SimpleConfig config = new SimpleConfig(CONFIG_DEF, props);
fieldName = config.getString(UUID_FIELD_NAME);
}
Tanımlanmış olan CONFIG_DEF’e göre bağlayıcı konfigürasyonunda belirtilmesi gereken değişkenler ekteki gibidir:
1
2
"transforms.insertuuid.type": "tr.gov.tubitak.bilgem.yte.smt.InsertUuid",
"transforms.insertuuid.uuid.field.name": "id",
Adım 3 - Her mesaja uygulanacak olan transformasyon işlemleri belirtilir. Örnekte; gelen her mesaja rastgele bir “UUID” değeri mesaj başlığı olarak eklenir. Bu başlığın anahtarı ise konfigürasyonda kullanıcının belirtmiş olacağı “fieldName” parametresinden gelen değer olacaktır.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Override
public R apply(R record) {
return insertUuid(record);
}
private R insertUuid(R record) {
Headers headers = record.headers();
SchemaAndValue schemaAndValue = new SchemaAndValue(Schema.STRING_SCHEMA, UUID.randomUUID().toString());
headers.add(fieldName, schemaAndValue);
return newRecord(record, headers);
}
protected R newRecord(R record, Headers headers) {
return record.newRecord(record.topic(), record.kafkaPartition(), record.keySchema(), record.key(), record.valueSchema(), record.value(), record.timestamp(), headers);
}
İlgili Java sınıfı derlenip JAR haline getirildikten sonra Debezium konteyneri içerisinde “kafka/connect/plugins” dizinine eklenerek doğrudan kullanılabilir.
16. Debezium İle Outbox Pattern Optimizasyonu
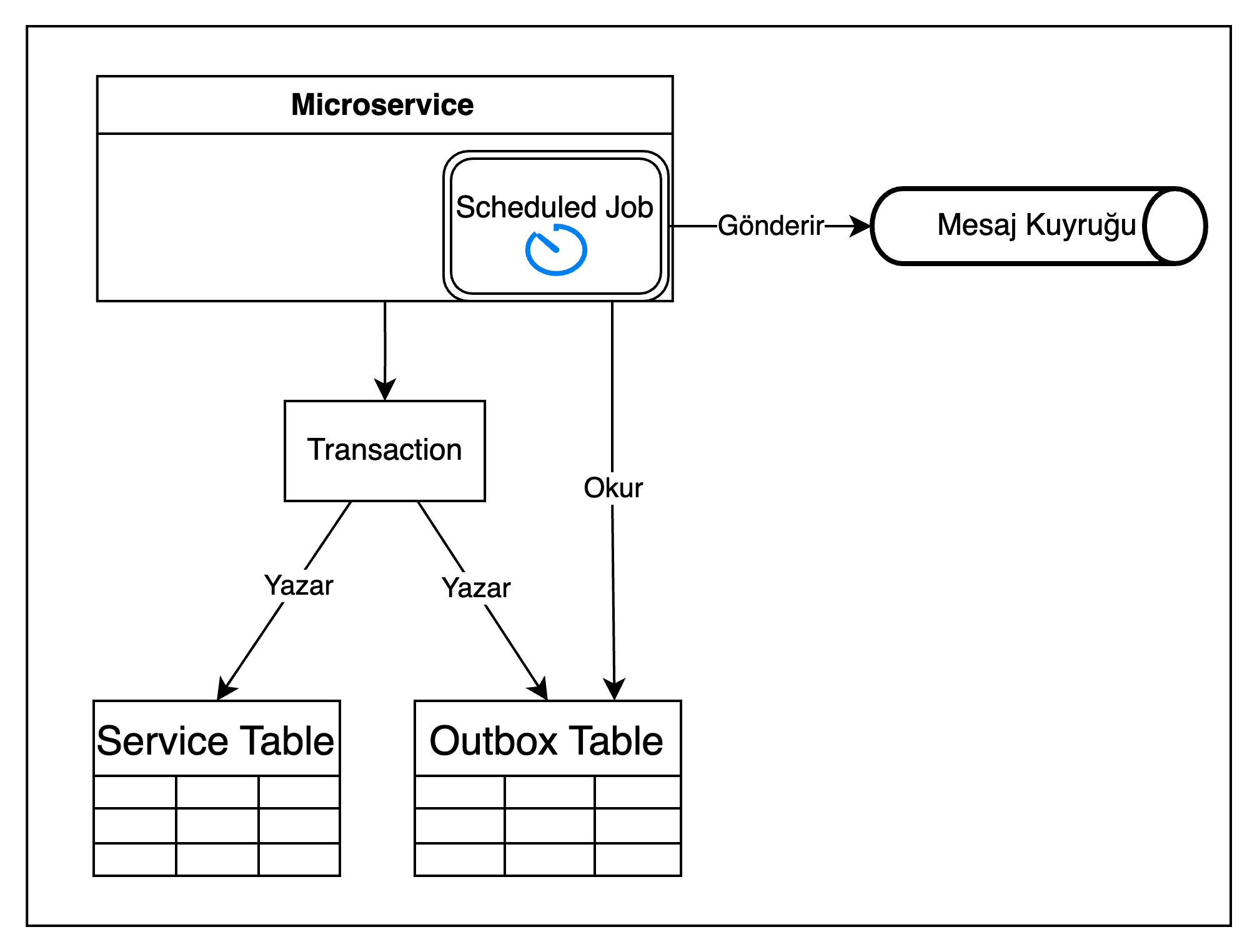
Geleneksel olarak Outbox Pattern için akış şeması ekteki gibidir:
Şekil 9: outbox pattern akış şeması
Bu yaklaşımda servis kendisini ilgilendiren değişiklik ile dış sisteme yollaması gereken mesaj içeriğini tek bir transaction içerisinde veri tabanına kaydeder. Bu yaklaşım; iki farklı sistemde yapılması gereken değişiklikler için servislerden herhangi birinin o an erişilebilir olmamasına karşı toleranslıdır (Bkz: Dual Write Problem).
Ancak bu yaklaşımın da belli dezavantajları mevcuttur:
- Scheduled Job’ın çok sık çalışması veri tabanındaki query sayısını arttıracak, seyrek çalışması mesajların iletimesini geciktirecektir.
- Dağıtık bir ortamda birden fazla mikroservis aynı anda outbox tablosunu okuyacak ve belli mesajların birden fazla kez yayınlanmasına sebep olacaktır.
- Yine birden fazla mikroservisin mesajları okumasından dolayı gönderilen mesajlar arasındaki sıra kaybedilecektir.
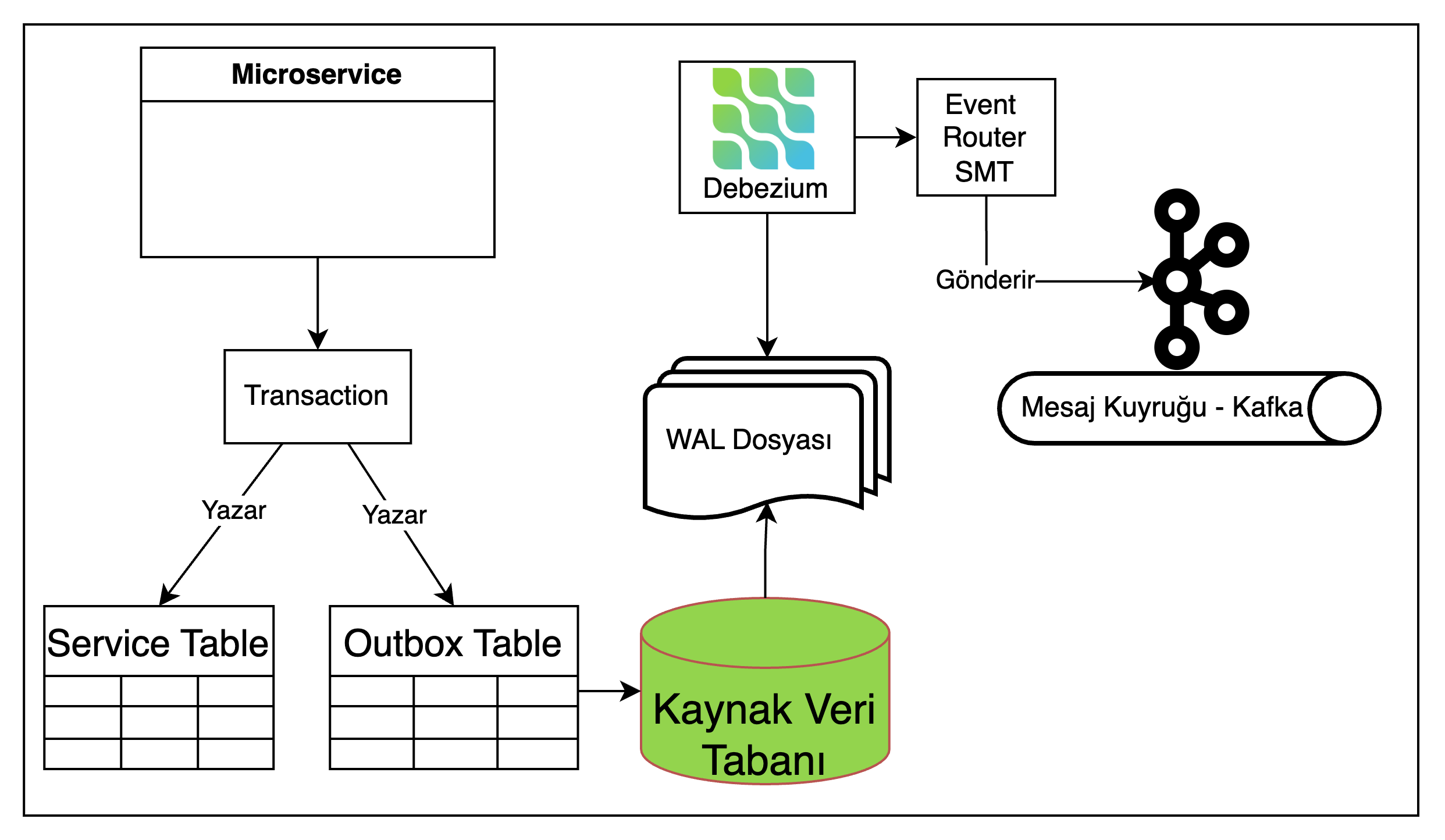
Debezium ile Outbox Pattern implementasyonunda ise bu sorunlar mevcut değildir.
Debezium ile outbox pattern için akış şeması ekteki gibidir:
Şekil 10: Debezium ile outbox pattern akış şeması
Bu yaklaşımda;
- Outbox Tablosunu sürekli sorgulayan bir scheduled job olmadığından veri tabanına atılan sorgu sayısı azalacak
- Scheduled Job gibi periyodik değil anlık çalıştığı için mesajlar gerçek zamanlı olarak gönderilecek
- Sistemde çalışan tek bir Debezium bulunduğu için concurrency (eş zamanlılık) ve lock (kilit) sorunları yaşanmayacak ve mesajlar sıralı olarak üretilecektir.
Debezium ile Outbox Pattern yaklaşımında Outbox Tablosu akıştan tamamen çıkarılabilir. Ancak gerçekleştirme kolaylığı açısından bir Outbox Tablosu’nun varlığı yine de tercih edilmektedir.
17. Debezium İle İlişkisel Verileri Aktarma
Kafka Connect mimarisinde ilişkisel verilerin aktarımı problemlidir. Bu problem, temelde ilişkisel veriler arasında aktarım sırasının korunamıyor olmasından doğmaktadır.
Bu mimaride, WAL dosyasindan okunan her değişiklik, değişikliğin gerçeklestiği tablo ismini taşıyan bir topice gönderilmektedir.
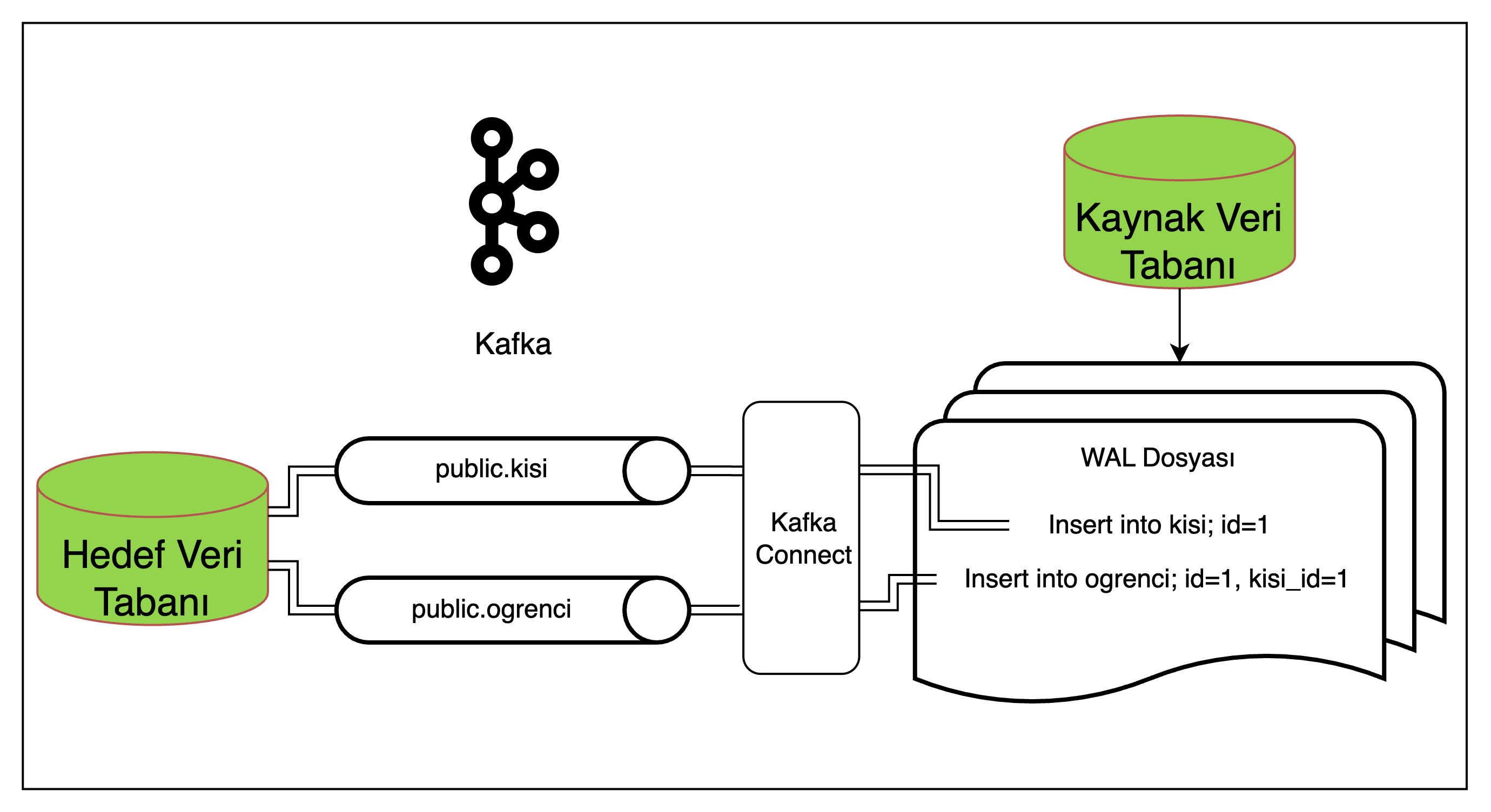
Şekil 11: Debezium ile ilişkisel veri aktarma akış şeması
Bu akışta Student tablosundaki person_id alanı person tablosundaki bir kayıt ile ilişkilidir. Hedef veri tabanında da aynı ilişki var ise, ancak id=1 olan person için kayit mesaji id=1 olan studentı içeren kayıt mesajından önce tüketilirse aktarım başarılı şekilde gerçekleşecektir.
SMT ile Kafka Connect’in ürettigi mesajlar değiştirilebilir; öyleyse bir çözum önerisi olarak tüm mesajların aynı topice yönlenmesi ve mesajın tüketilmesi sırasında mesajın içerdiği veriye göre ilgili tabloya kaydedilmesi düşünülebilir ancak bu yaklaşım da mesaj tüketim sırasında garanti sağlamamaktadır.
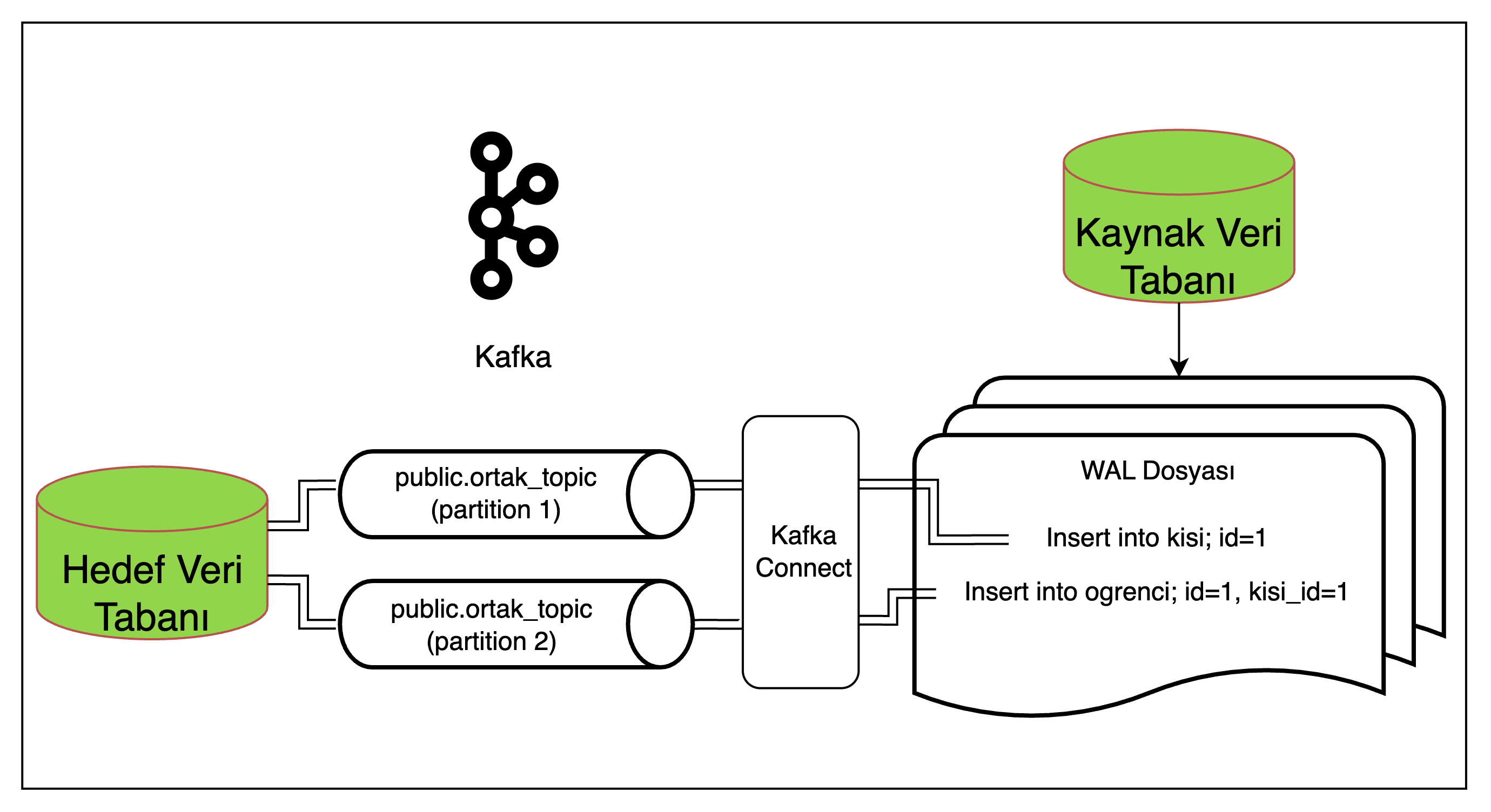
Şekil 12: İlişkisel veri aktarımında partition çözümü
Bu akışta ise birbiriyle ilişkili veriler farkli partitionlara yönlenmis olabilir ve yine kayit mesajlarının tüketim sırasında bir garanti verilemez. Ayrıca bir topic’e birden farklı mesaj tipi göndermek tercih edilmeyen bir yaklaşımdır.
17.1. İlişkisel Veri Aktarımında Kullanılabilecek Yaklaşımlar
17.1.1. Veri Denormalizasyonu
En yaygin kullanılan çözümlerden bir tanesi; verinin denormalize edilmesidir. Bu yaklaşımda ilişkisel tüm tablolarda bulunan veriler tek bir tabloda birleştirilir, ve aktarım bu tablo üzerinden sağlanır. Bu yaklaşım ilişkisel bir veri tabanından ilişkisel olmayan bir veri tabanına aktarımda da uygun bir çözüm olmaktadır.
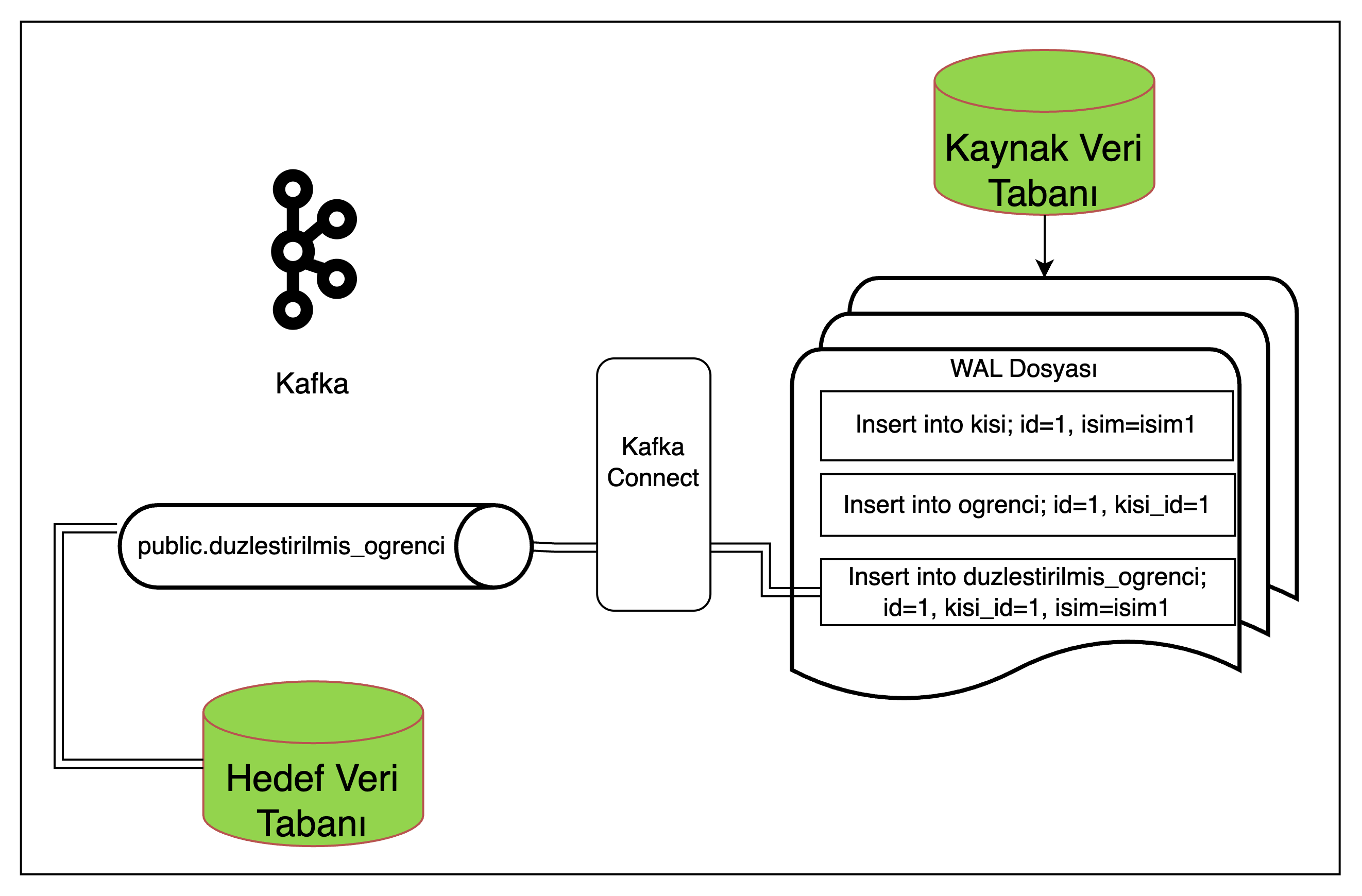
Şekil 13: İlişkisel veri aktarımında düzleştirilmiş tablo yapısı çözümü
Örnekte denormalized_student tablosu person ve student tablolarından tüm verileri içeren tablodur. Bu tablo ile diğer tablolar arasında herhangi bir ilişki bulunmadığından bu tablodan yapılan aktarımlar da ilişkisel aktarım sorunlarıyla karşılaşılmayacak aynı zamanda aktarım NoSQL veri tabanlarina da sağlıklı şekilde yapılabilecektir.
17.1.2. KSQL
İlişkinin kesin olarak korunmasi gerekiyorsa; sistemi karmaşıklaştırmadan uygulanabilecek en etkili çözüö KSQL kullanmaktır. KSQL; Kafka içerisinde SQL sorguları yazmaya yarayan ve Kafka’daki verileri manipüle etmeye yarayan bir platformdur.
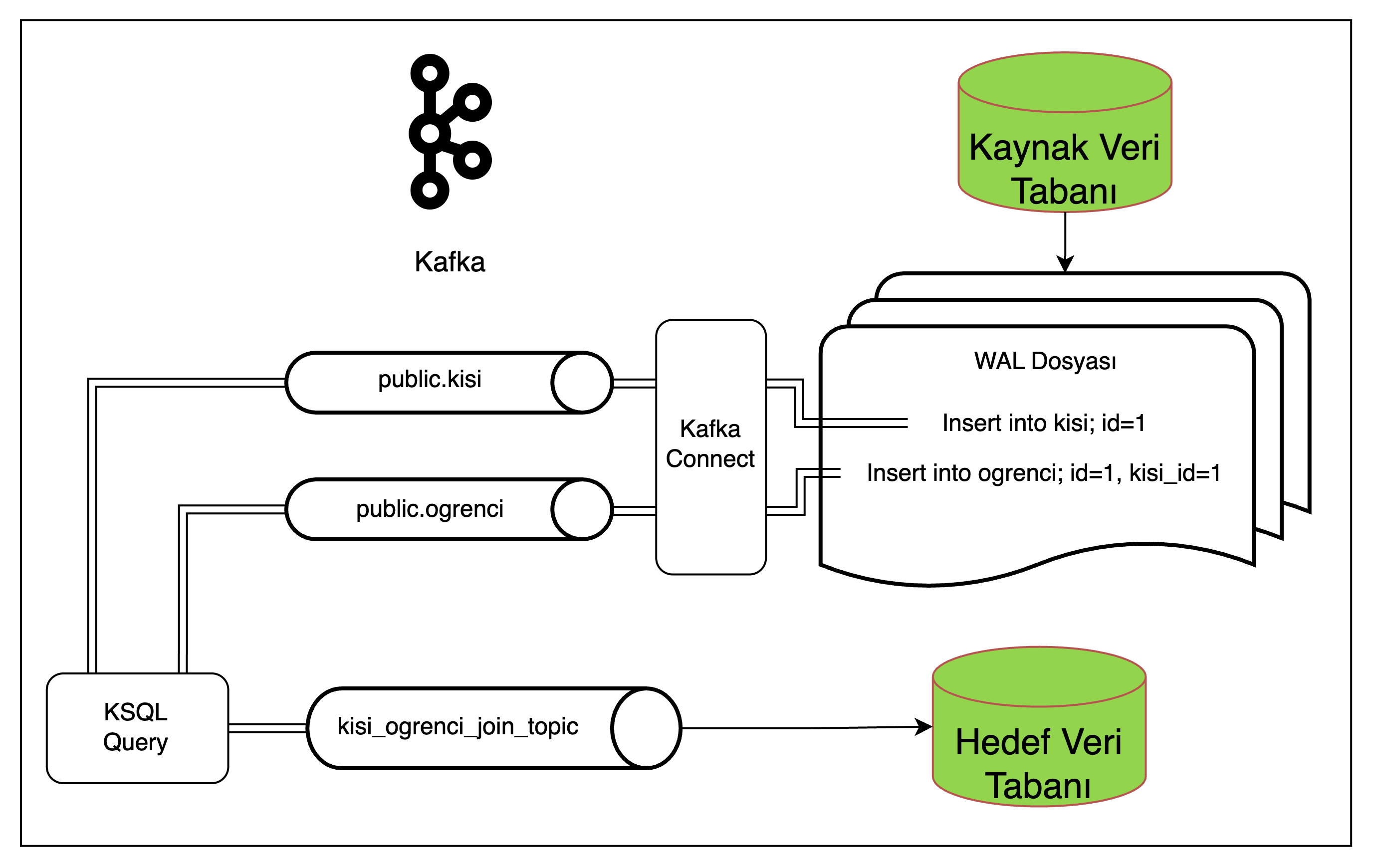
Şekil 14: İlişkisel veri aktarımında ksqlDB çözümü
Akışta person ve student tablolari KSQL ile joinlenerek; iki verinin birleştirilmiş halini içeren 3. bir topice yönlendirilmektedir. Böylece hedef veri tabanında joinlenmiş yapıdan iliskişel veriler ayrıştırılıp ilgili tablolara kaydedilebilir.
İlişkisel veriyi içeren kayit mesajı tek seferde tüketileceğinden verilerin kaydedilmesi sırası önem arz etmeyecek, hedef veri tabanında ilişki hatası alınmayacaktır.